

This post is a guest post from Dr Andreas Kempa-Liehr, a data scientist who is one of the newest members of academic staff in the Department of Engineering Science.
Decisions under uncertainty
The only certain thing about the future is its uncertainty. Yet we are making decisions for the very next future, both in our private life and the business/engineering processes, we are responsible for. The enablers for these decisions are our very individual skills, which we have learned from interactions with our environment. This kind of knowledge can be interpreted as our very personal, intrinsic model of the environment, which we are using for solving problems. It comprises both our expectation of what is likely to happen and the understanding of how to achieve the desired outcome.
The problem is that people are not very good in making decisions under uncertainty, which might be boiled down to the following quote of Amos Tversky, who worked with Nobel-prize winner Daniel Kahneman [1] on the discovery of systematic cognitive biases:
“The evidence reported here and elsewhere indicates that both qualitative and quantitative assessments of uncertainty are not carried out in a logically coherent fashion, and one might be tempted to conclude that they should not be carried out at all.” [2]
Does this mean, that objective algorithms should be able to make better microdecisions? Yes, but for implementing them one needs a clear understanding on what the meaning of better is (Domain Expertise) in order to develop models for predicting the information needed for doing better (Data Science) and models for making decisions from the provided information (Operations Research). The critical part is the mathematical interface between predictive model and decision model, which should not be a single number of a predicted outcome (point estimate) but a probability for each possible outcome given the actual circumstances (conditional probability distribution). The important point is that conditional probability distributions allow to systematically take into account the uncertainty of the predictions such that cost-optimal decisions under uncertainty can be made.
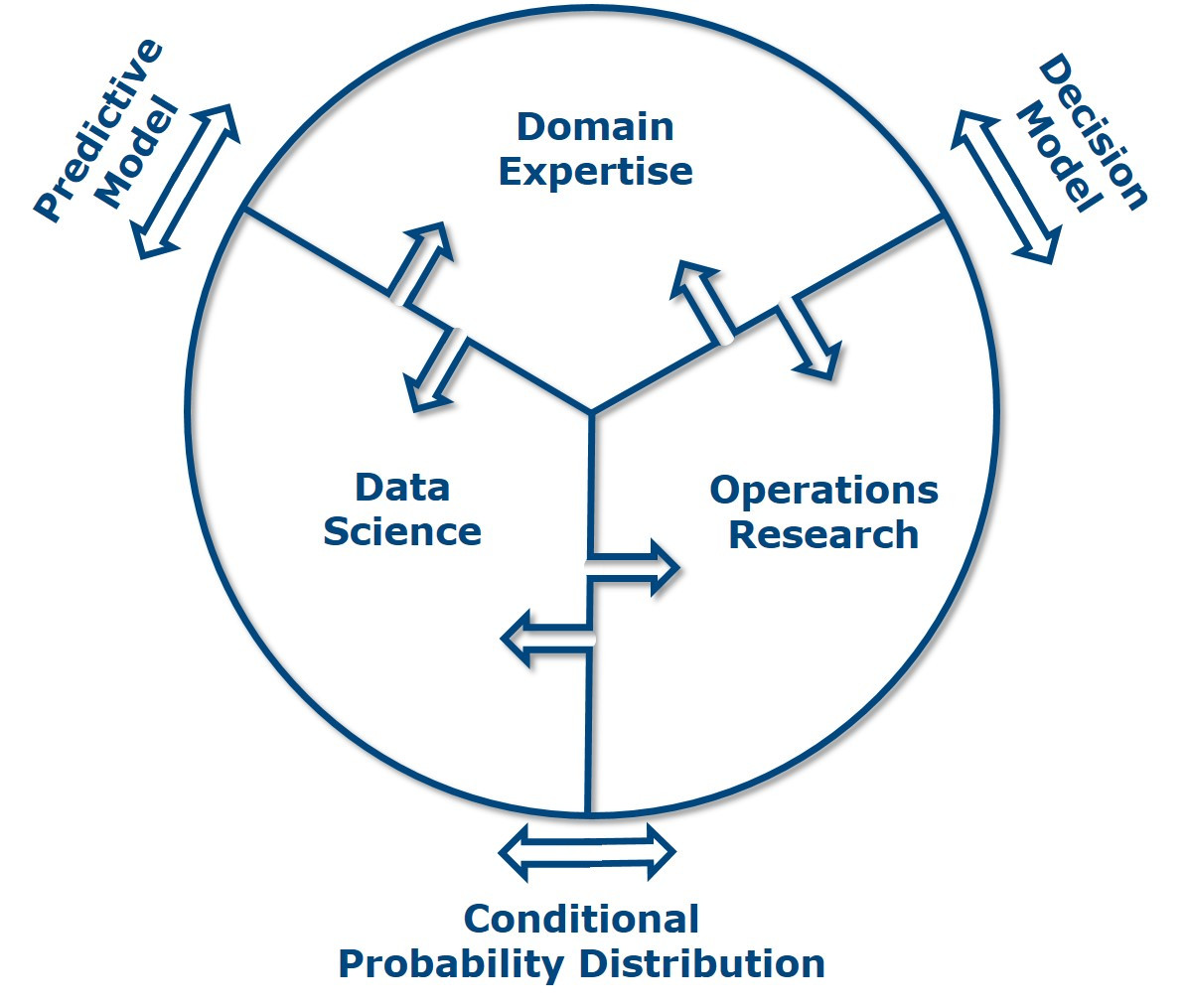
Automating Micro-Decisions
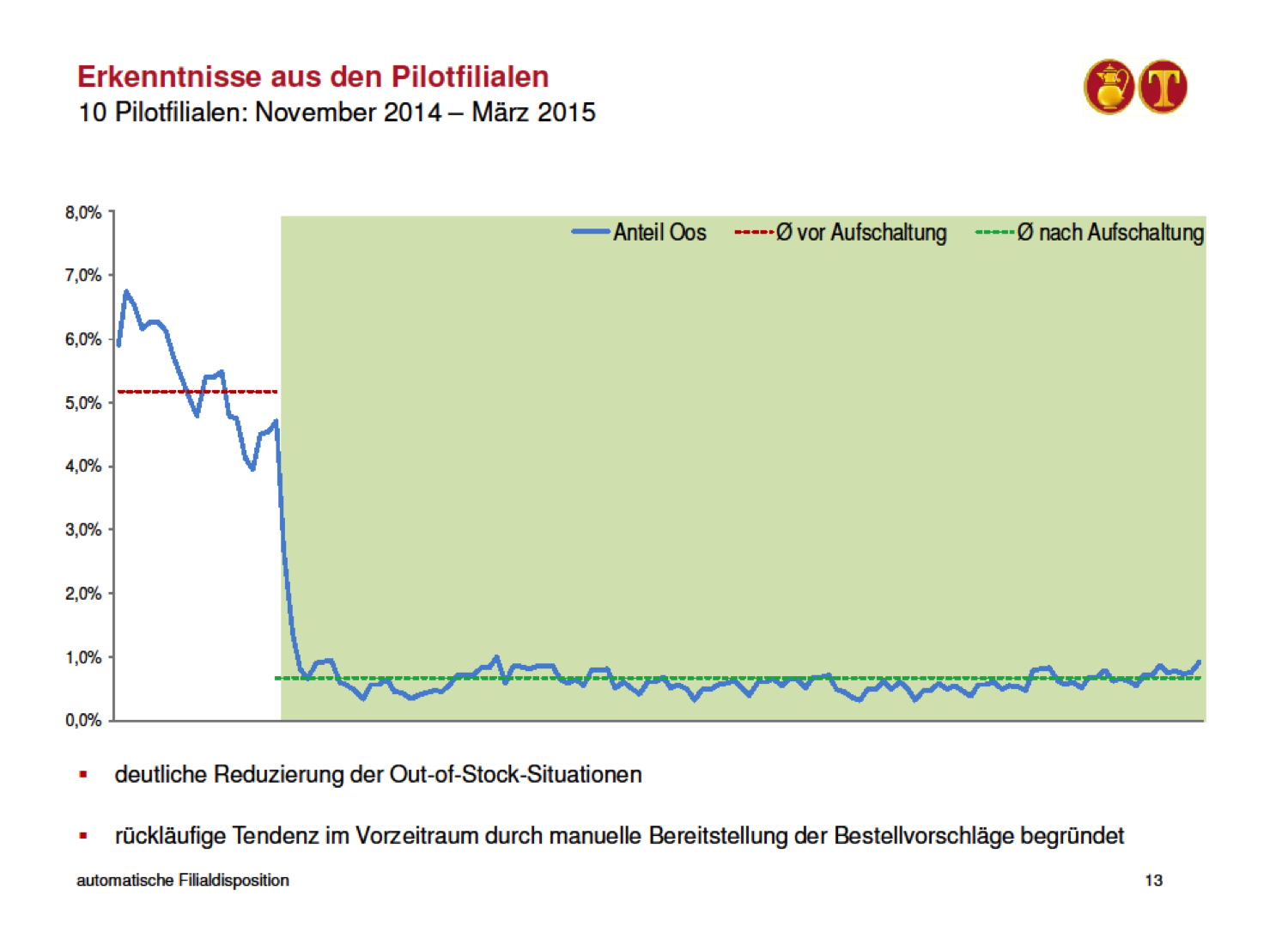
Have a look at the following slide, which has been captured from a presentation of M. Michaelis given at the 4th Big Data & Analytics Congress [3]. It shows the out-of-stock rate of 10 stores, which had their replenishment processes being switched to a data driven approach based on conditional probability distributions for expected sales. In the beginning the suggested replenishment orders could be altered by staff, but after a transition period the processes were switched to full automation. The slide is in German, but the diagram speaks for itself: It shows the plummeting of the out-of-stock rates after switching to fully automated replenishment orders.
References
[1] D. Kahneman. Thinking, Fast and Slow. Farrar, Straus and Giroux, New York, 2011.
[2] Amos Tversky and Derek J. Koehler. Support theory: A nonextensional representation of subjective probability. Psychological Review, 101(4):547–567, 1994.
[3] Mark Michaelis. Case Study Kaiser’s Tengelmann: Prognoseverfahren im Dispositionsumfeld.